The initial work in the ‘Backpropagation Algorithm’ started in the 1980’s and led to an explosion of interest in Neural Networks and the application of backpropagation
The ‘Backpropagation’ algorithm computes the minimum of an error function with respect to the weights in the Neural Network. It uses the method of gradient descent. The combination of weights in a multi-layered neural network, which minimizes the error/cost function is considered to be a solution of the learning problem.

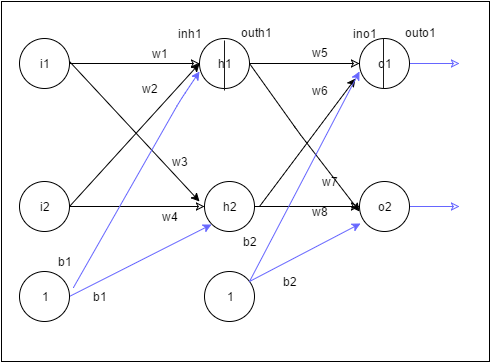
In the Neural Network above

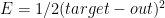
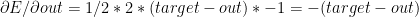

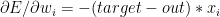
 Checkout my book ‘Deep Learning from first principles: Second Edition – In vectorized Python, R and Octave’. My book starts with the implementation of a simple 2-layer Neural Network and works its way to a generic L-Layer Deep Learning Network, with all the bells and whistles. The derivations have been discussed in detail. The code has been extensively commented and included in its entirety in the Appendix sections. My book is available on Amazon as paperback ($18.99) and in kindle version($9.99/Rs449).
Checkout my book ‘Deep Learning from first principles: Second Edition – In vectorized Python, R and Octave’. My book starts with the implementation of a simple 2-layer Neural Network and works its way to a generic L-Layer Deep Learning Network, with all the bells and whistles. The derivations have been discussed in detail. The code has been extensively commented and included in its entirety in the Appendix sections. My book is available on Amazon as paperback ($18.99) and in kindle version($9.99/Rs449).
Perceptrons and single layered neural networks can only classify, if the sample space is linearly separable. For non-linear decision boundaries, a multi layered neural network with backpropagation is required to generate more complex boundaries.The backpropagation algorithm, computes the minimum of the error function in weight space using the method of gradient descent. This computation of the gradient, requires the activation function to be both differentiable and continuous. Hence the sigmoid or logistic function is typically chosen as the activation function at every layer.
This post looks at a 3 layer neural network with 1 input, 1 hidden and 1 output. To a large extent this post is based on Matt Mazur’s detailed “A step by step backpropagation example“, and Prof Hinton’s “Neural Networks for Machine Learning” at Coursera and a few other sources.
While Matt Mazur’s post uses example values, I generate the formulas for the gradient derivatives for each weight in the hidden and input layers. I intend to implement a vector version of backpropagation in Octave, R and Python. So this post is a prequel to that.
The 3 layer neural network is as below
Some basic derivations which are used in backpropagation
Chain rule of differentiation
Let y=f(u)
and u=g(x) then

An important result
Let 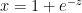
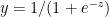

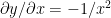
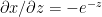
Using the chain rule of differentiation we get
Therefore 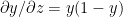
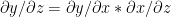
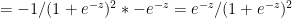
1) Feed forward network
The net output at the 1st hidden layer
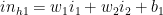
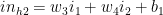
The sigmoid/logistic function function is used to generate the activation outputs for each hidden layer. The sigmoid is chosen because it is continuous and also has a continuous derivative
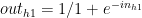

The net output at the output layer
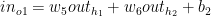
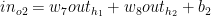
Total error
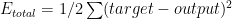
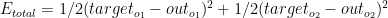
2)The backwards pass
In the backward pass we need to compute how the squared error changes with changing weight. i.e we compute 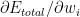
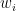
A squared error is assumed
Error gradient with
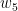

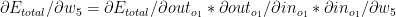
Since
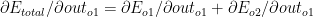
![\partial E _{total}/\partial out_{o1} = \partial /\partial _{out_{o1}}[1/2(target_{01}-out_{01})^{2}- 1/2(target_{02}-out_{02})^{2}]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cpartial+E+_%7Btotal%7D%2F%5Cpartial+out_%7Bo1%7D+%3D+%5Cpartial+%2F%5Cpartial+_%7Bout_%7Bo1%7D%7D%5B1%2F2%28target_%7B01%7D-out_%7B01%7D%29%5E%7B2%7D-+1%2F2%28target_%7B02%7D-out_%7B02%7D%29%5E%7B2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
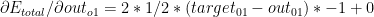
Now considering the 2nd term in (B)
![\partial out_{o1}/\partial in_{o1} = \partial/\partial in_{o1} [1/(1+e^{-in_{o1}})]](https://s0.wp.com/latex.php?latex=%5Cpartial+out_%7Bo1%7D%2F%5Cpartial+in_%7Bo1%7D+%3D+%5Cpartial%2F%5Cpartial+in_%7Bo1%7D+%5B1%2F%281%2Be%5E%7B-in_%7Bo1%7D%7D%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Using result (A)
![\partial out_{o1}/\partial in_{o1} = \partial/\partial in_{o1} [1/(1+e^{-in_{o1}})] = out_{o1}(1-out_{o1})](https://s0.wp.com/latex.php?latex=%C2%A0%5Cpartial+out_%7Bo1%7D%2F%5Cpartial+in_%7Bo1%7D+%3D+%5Cpartial%2F%5Cpartial+in_%7Bo1%7D+%5B1%2F%281%2Be%5E%7B-in_%7Bo1%7D%7D%29%5D+%3D+out_%7Bo1%7D%281-out_%7Bo1%7D%29&bg=ffffff&fg=000000&s=0&c=20201002)
The 3rd term in (B)
![\partial in_{o1}/\partial w_{5} = \partial/\partial w_{5} [w_{5}*out_{h1} + w_{6}*out_{h2}] = out_{h1}](https://s0.wp.com/latex.php?latex=%C2%A0%5Cpartial+in_%7Bo1%7D%2F%5Cpartial+w_%7B5%7D+%3D+%5Cpartial%2F%5Cpartial+w_%7B5%7D+%5Bw_%7B5%7D%2Aout_%7Bh1%7D+%2B+w_%7B6%7D%2Aout_%7Bh2%7D%5D+%3D+out_%7Bh1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
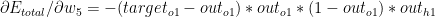
Having computed 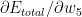

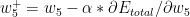
If we do this for 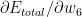

3)Hidden layer

We now compute how the total error changes for a change in weight
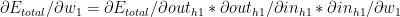
Using

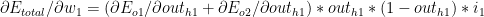
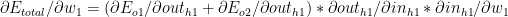
Considering the 1st term in (C)
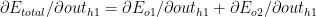
Now
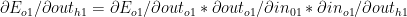
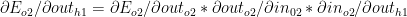
which gives the following
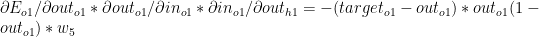
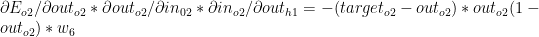
Combining (D), (E) & (F) we get
![\partial E_{total}/\partial w_{1} = -[(target_{o1}-out_{o1}) *out_{o1}(1-out_{o1})*w_{5} + (target_{o2}-out_{o2}) *out_{o2}(1-out_{o2})*w_{6}]*out_{h1}*(1-out_{h1})*i_{1}](https://s0.wp.com/latex.php?latex=%5Cpartial+E_%7Btotal%7D%2F%5Cpartial+w_%7B1%7D+%3D+-%5B%28target_%7Bo1%7D-out_%7Bo1%7D%29+%2Aout_%7Bo1%7D%281-out_%7Bo1%7D%29%2Aw_%7B5%7D+%2B+%28target_%7Bo2%7D-out_%7Bo2%7D%29+%2Aout_%7Bo2%7D%281-out_%7Bo2%7D%29%2Aw_%7B6%7D%5D%2Aout_%7Bh1%7D%2A%281-out_%7Bh1%7D%29%2Ai_%7B1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
This can be represented as
![\partial E_{total}/\partial w_{1} = -\sum_{i}[(target_{oi}-out_{oi}) *out_{oi}(1-out_{oi})*w_{j}]*out_{h1}*(1-out_{h1})*i_{1}](https://s0.wp.com/latex.php?latex=%5Cpartial+E_%7Btotal%7D%2F%5Cpartial+w_%7B1%7D+%3D+-%5Csum_%7Bi%7D%5B%28target_%7Boi%7D-out_%7Boi%7D%29+%2Aout_%7Boi%7D%281-out_%7Boi%7D%29%2Aw_%7Bj%7D%5D%2Aout_%7Bh1%7D%2A%281-out_%7Bh1%7D%29%2Ai_%7B1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
With this derivative a new value of 
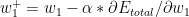
Hence there are 2 important results
At the output layer we have
a)
At each hidden layer we compute
b)
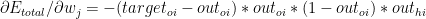
![\partial E_{total}/\partial w_{k} = -\sum_{i}[(target_{oi}-out_{oi}) *out_{oi}(1-out_{oi})*w_{j}]*out_{hk}*(1-out_{hk})*i_{k}](https://s0.wp.com/latex.php?latex=%5Cpartial+E_%7Btotal%7D%2F%5Cpartial+w_%7Bk%7D+%3D+-%5Csum_%7Bi%7D%5B%28target_%7Boi%7D-out_%7Boi%7D%29+%2Aout_%7Boi%7D%281-out_%7Boi%7D%29%2Aw_%7Bj%7D%5D%2Aout_%7Bhk%7D%2A%281-out_%7Bhk%7D%29%2Ai_%7Bk%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Backpropagation, was very successful in the early years, but the algorithm does have its problems for e.g the issue of the ‘vanishing’ and ‘exploding’ gradient. Yet it is a very key development in Neural Networks, and the issues with the backprop gradients have been addressed through techniques such as the momentum method and adaptive learning rate etc.
In this post. I derive the weights at the output layer and the hidden layer. As I already mentioned above, I intend to implement a vector version of the backpropagation algorithm in Octave, R and Python in the days to come.
Watch this space! I’ll be back
P.S. If you find any typos/errors, do let me know!
References
1. Neural Networks for Machine Learning by Prof Geoffrey Hinton
2. A Step by Step Backpropagation Example by Matt Mazur
3. The Backpropagation algorithm by R Rojas
4. Backpropagation Learning Artificial Neural Networks David S Touretzky
5. Artificial Intelligence, Prof Sudeshna Sarkar, NPTEL
Also see my other posts
1. Introducing QCSimulator: A 5-qubit quantum computing simulator in R
2. Design Principles of Scalable, Distributed Systems
3. A method for optimal bandwidth usage by auctioning available bandwidth using the OpenFlow protocol
4. De-blurring revisited with Wiener filter using OpenCV
5. GooglyPlus: yorkr analyzes IPL players, teams, matches with plots and tables
6. Re-introducing cricketr! : An R package to analyze performances of cricketers
To see all my posts go to ‘Index of Posts‘


13 thoughts on “Neural Networks: The mechanics of backpropagation”